Todo o conteúdo fornecido neste post destina-se exclusivamente a fins educacionais, de estudo e desenvolvimento profissional e pessoal. As informações aqui apresentadas são para serem utilizadas de forma ética e profissional, em conformidade com todas as leis e regulamentos aplicáveis.
Informações iniciais
Arquivos .js
Seja você um profissional de Red Team, estudante, pesquisador ou Bug Hunter, um vetor importante para busca de informações em aplicações web, são os arquivos .js. Muitas vezes esses arquivos acabam passando despercebidos por parte da equipe de desenvolvimento com informações sensíveis dentro desses arquivo. Dessa forma dados que podem conter informações confidenciais acabam expostos.
Portanto, enumerar esses arquivos em seu ambiente ou escopo de pentesting/bug-hunting é um passo muito relevante para aquisição de informações.
Expressões regulares
As técnicas de expressões regulares (ou regex), são extremamente importantes para encontrar dados sensíveis em arquivos .js, como senhas, tokens, links para apis, AWS/Google Keys ou informações pessoais, devido à sua capacidade de buscar padrões específicos de texto de forma eficiente. Usando o regex, é possível criar padrões personalizados que correspondam exatamente aos tipos de dados sensíveis que estamos procurando, aumentando a precisão da busca.
As regex permitem realizar verificações em massa em grandes volumes de texto (ou logs, em um próximo artigo ensinarei a procurar dados em logs do Wazuh e Graylog) de forma automatizada, o que economiza tempo e esforço.
- Site para verificar suas expressões: https://regex101.com/
- Wikipedia: https://en.wikipedia.org/wiki/Regular_expression
- Artigo no medium: https://medium.com/xp-inc/regex-um-guia-pratico-para-express%C3%B5es-regulares-1ac5fa4dd39f
O que é um subdomínio?
Um subdomínio é um domínio de segundo nível que faz parte de um domínio maior. Por exemplo, www.blog.jardel.tec.br seria um subdomínio de jardel.tec.br .
Os subdomínios podem ser usados para diversos fins, como hospedar um blog, um site de comércio eletrônico ou até mesmo um site totalmente diferente do domínio raiz. Os subdomínios são frequentemente usados para segregar diferentes serviços ou funcionalidades dentro de uma organização.
O que é enumeração de subdomínios?
A enumeração de subdomínios é o processo de identificação de todos os subdomínios de um determinado domínio. Isso pode ser útil para diversos fins, como identificar alvos potenciais para um trabalho de bug hunting e pentesting ou simplesmente para fins organizacionais.
Ferramentas necessárias
- Go – Muitas da ferramentas são escritas em Go, portanto ..
https://go.dev/doc/install - Enumeração de subdomínios:
https://github.com/projectdiscovery/subfinder
https://github.com/tomnomnom/assetfinder
https://github.com/Findomain/Findomain - Verificar subdomínios online
https://github.com/projectdiscovery/httpx - Burp Suite (uma das melhores ferramentas existente)
https://portswigger.net/burp/communitydownload - Proxy para trabalhar junto com o BurpSuite
https://getfoxyproxy.org/ - Enumeração de JS Files. Para esse artigo uso o getJS, tentei o uso do Katana, mas ele gastou mais recursos e trouxe menos links em vários testes que realizei.
https://github.com/003random/getJS - Encontrando informações nos arquivos.
https://github.com/raoufmaklouf/jsecret - Demais ferramentas
https://github.com/tomnomnom/anew
https://github.com/s0md3v/uro/tree/main
Configurando Proxy
Burp Suite
- Abra o Burpsuite
- Selecione “Proxy”
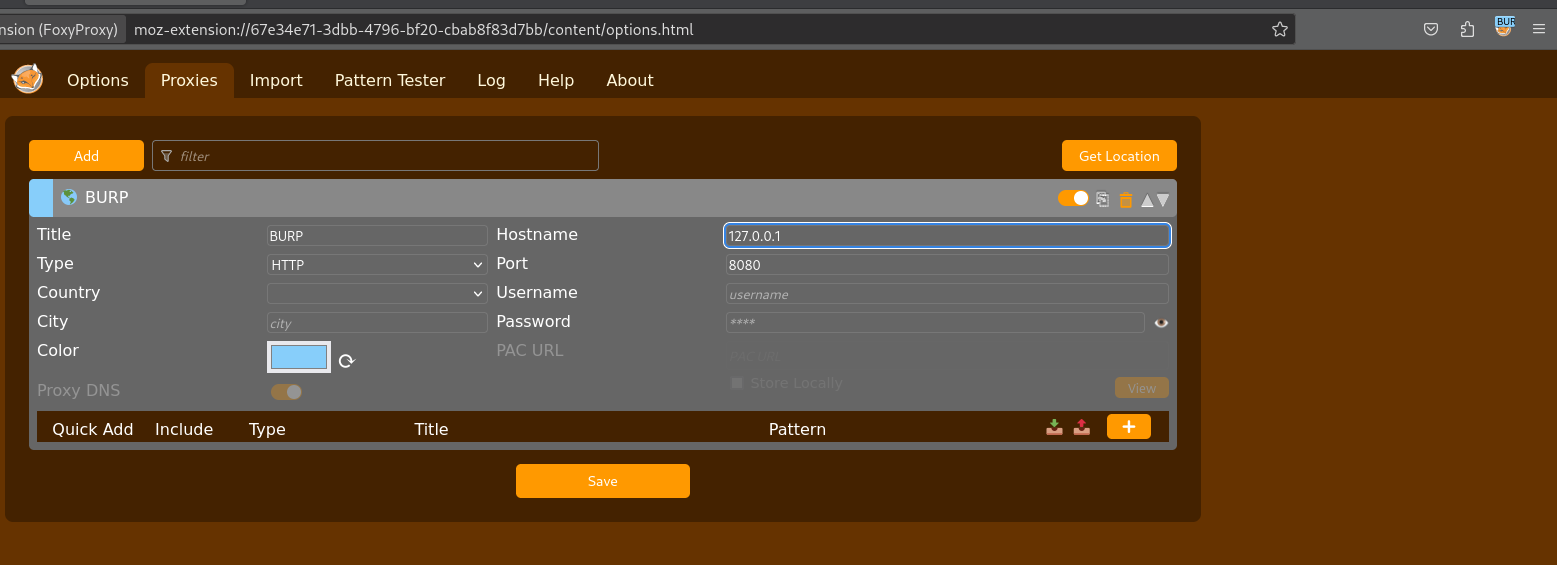
- Configure o servidor Proxy de acordo com a imagem, editando as informações do proxy de acordo com sua rede.
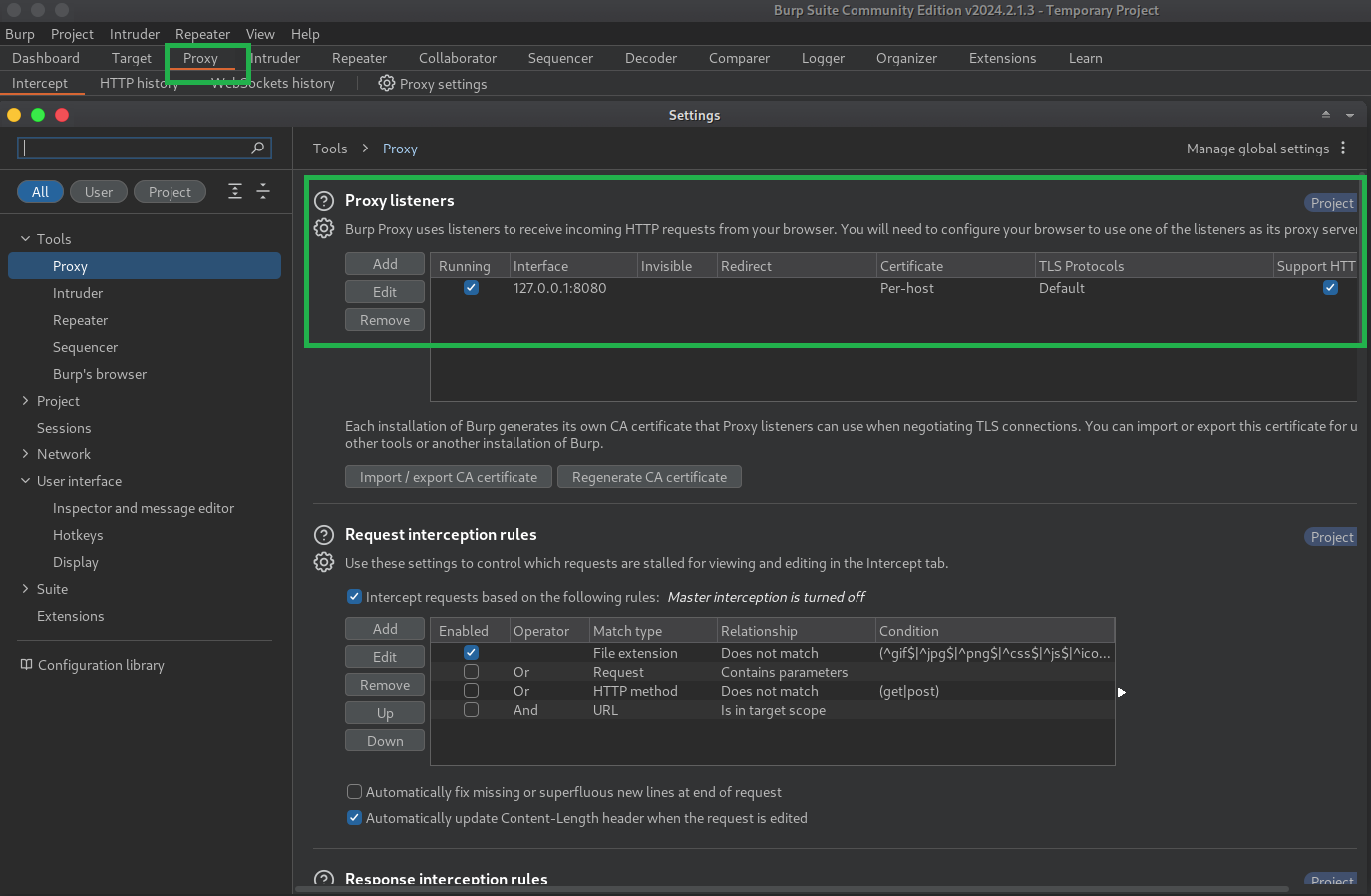
Como iremos trabalhar com vários links, eu pessoalmente prefiro desabilitar o “Request Interception Rules” do Burp”, para isso, basta desmarcar a opção:
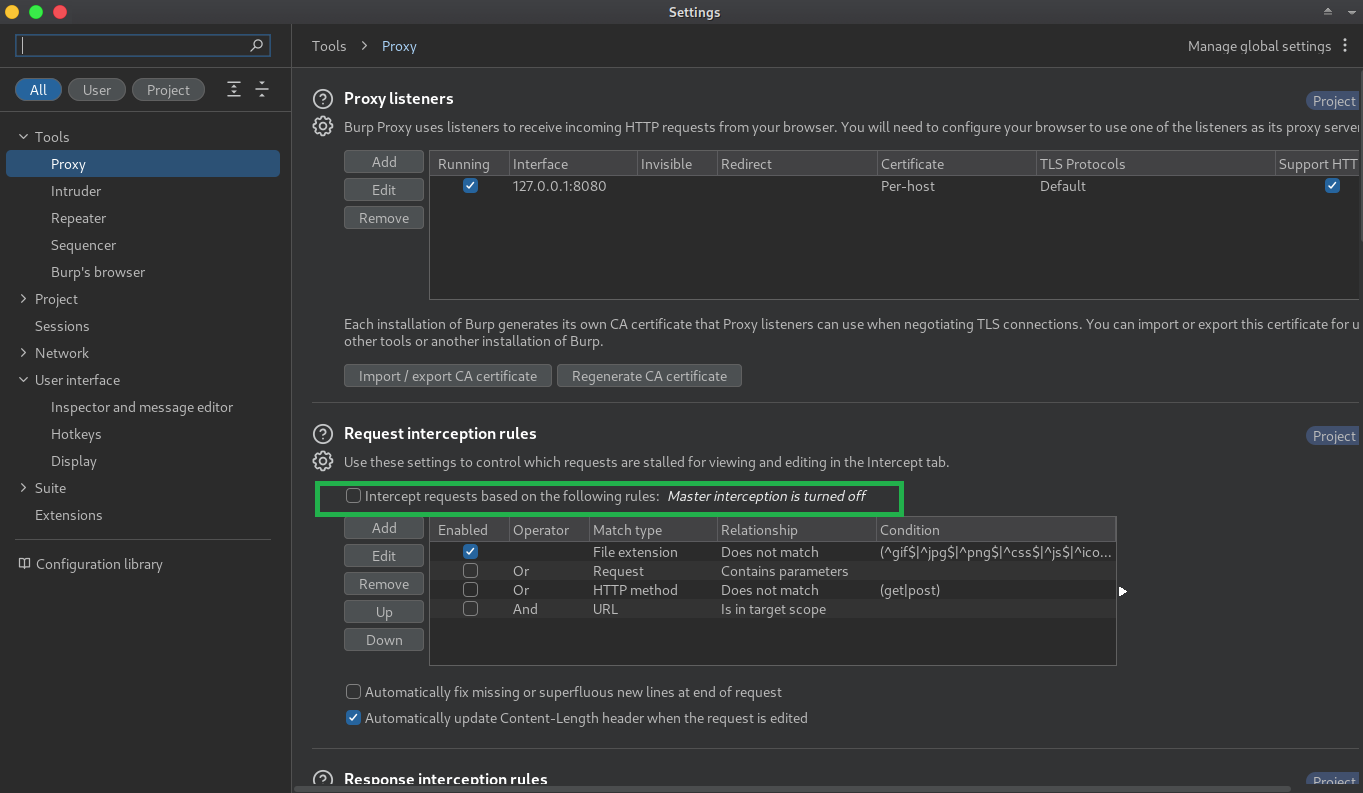
Dessa forma todas as requisições ao proxy serão automaticamente aceitas, sem precisar clicar em foward.
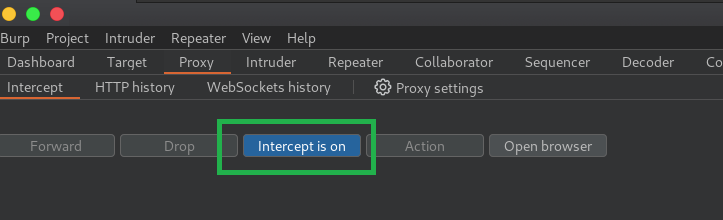
Intercept
Sempre deixe o Intercept em modo on.
Configurando certificado
- Se for a primeira vez que irá utilizar o Burp como proxy, será necessário configurar o certificado no Firefox, para isso, leia a documentação oficial.: https://portswigger.net/burp/documentation/desktop/external-browser-config/certificate
Foxy Proxy
- Faça o download o FoxyProxy e adicione ao Firefox (ou chrome, vai da sua escolha).
- Configuração é simples, crie um proxy no mesmo endereço do Burp Suite
Script de Recon
- O script abaixo receberá o valor do dominio principal informado na tela
- Irá realizar a enumeração dos subdomínios com as quatro ferramentas
- Verificar os subdomínios online
- Realizar a enumeração dos links com arquivos .js, salvando-os em um arquivo de texto.
- Com a ferramenta jsecret de forma automática procurar por dados sensíveis , salvando o resultado em um arquivo de texto.
- Eu gosto de trabalhar com pastas para cada fase do Recon, pois no futuro fica mais fácil verificar resultados de recon, alterar e trabalhar com novas ferramentas. No caso use o comando para criar as pastas “mkdir -p /home/kali/02-JS_Files && mkdir -p /home/kali/03-HTTPX && mkdir -p /home/kali/04-JS_Secrets”
- Sinta-se livre para editar, melhorar da forma que melhor te agradar.
Criando o script
- Para funcionamento, crie o script em uma pasta com o nome da sua escolha, por exemplo recon.sh
- No terminal digite chmod +x recon.sh para dar a permissão de execução do script
- Para executar o script, no terminal digite ./recon.sh
#!/bin/bash
echo "----------------------------------------------------"
echo "----------------------------------------------------"
echo "What URL to recon?"
echo "----------------------------------------------------"
echo "----------------------------------------------------"
read url
# Create a folder to recon
if [ ! -d "$domains_folder/$url" ]; then
mkdir -p "$domains_folder/$url"
fi
# Folders
domains_folder="/home/kali/01-Domains"
js_folder="/home/kali/02-JS_Files"
httpx_folder="/home/kali/03-HTTPX"
js_secrets"/home/kali/04-JS_Secrets"
############################################
# SUDOMAINS ENUM
############################################
echo ----------------------------------------------------
echo "Phase 1: Performing subomain disconvery ..."
echo ----------------------------------------------------
cd $domains_folder
echo ----------------------------------------------------
echo "Phase 1.1: Using Subfinder ..."
echo ----------------------------------------------------
subfinder -d $url | anew $domains_folder/subfinder.txt
echo ----------------------------------------------------
echo "Phase 1.2: Using AssetFinder ..."
echo ----------------------------------------------------
assetfinder -subs-only $url | anew $domains_folder/assetfinder.txt
echo ----------------------------------------------------
echo "Phase 1.3 Using Findoman.."
echo ----------------------------------------------------
findomain -t $url -q | anew $domains_folder/findomain.txt
echo ----------------------------------------------------
echo "Phase 01.4 CRT.SH..."
echo ----------------------------------------------------
curl -s "https://crt.sh/?q=%25.$url&output=json" | jq -r '.[].name_value' | sed 's/\*\.//g' | anew $domains_folder/crt-sh.txt
echo ----------------------------------------------------
echo "Phase 1.5: Joining all files in alldomains."
echo ----------------------------------------------------
cat subfinder.txt assetfinder.txt findomain.txt crt-sh.txt | anew >> $domains_folder/alldomains.txt
############################################
# HTTPX Filter
############################################
# Httpx Verify online domains and save to a list
echo ----------------------------------------------------
echo "Phase 2:0 Verify online domains and save to a list with HTTPX ..."
echo ----------------------------------------------------
httpx -silent -l $domains_folder/alldomains.txt -o $httpx_folder/$url.txt
###################################################
# Javascript Enumeration
###################################################
echo ----------------------------------------------------
echo "Phase 3.0: Javascript Enumeration ..."
echo ----------------------------------------------------
cat $httpx_folder/$url.txt | getJS --complete | httpx | uro >> $js_folder/$url.txt
echo ----------------------------------------------------
echo "Phase 4.0: FindSecrets on .JS ..."
echo ----------------------------------------------------
cat $js_folder/$url.txt | jsecret >> $js_secrets/$url.txtApós o fim do script, você já terá alguns resultados da busca de .JS com a ferramenta jsecret na pasta que foi criada.
Burp Suite Scan
Voltando ao Burp Suite clique em:
- Extensions
- BApp Store
- Selecione “Sensitive Discoverer”
- Clique em Install
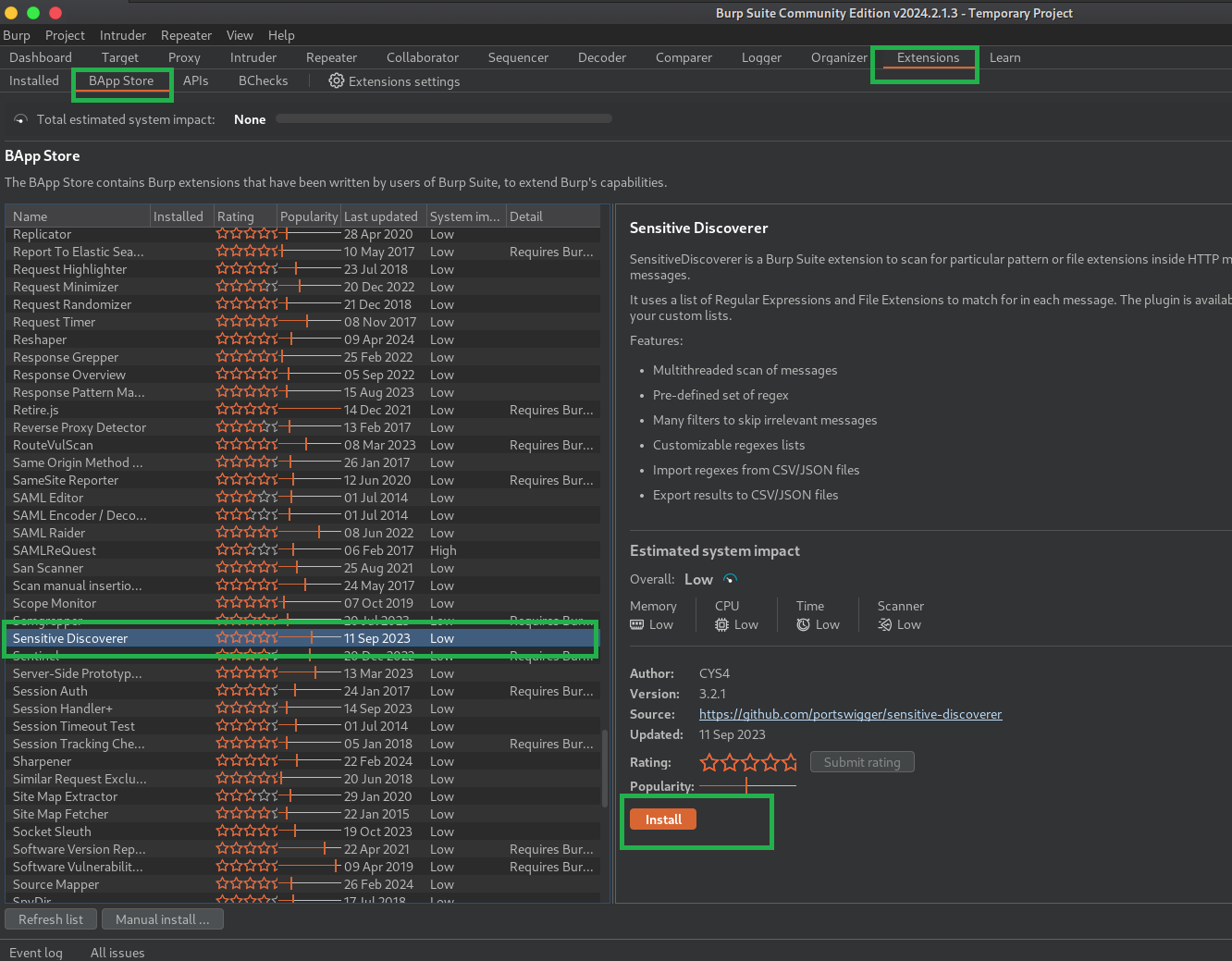
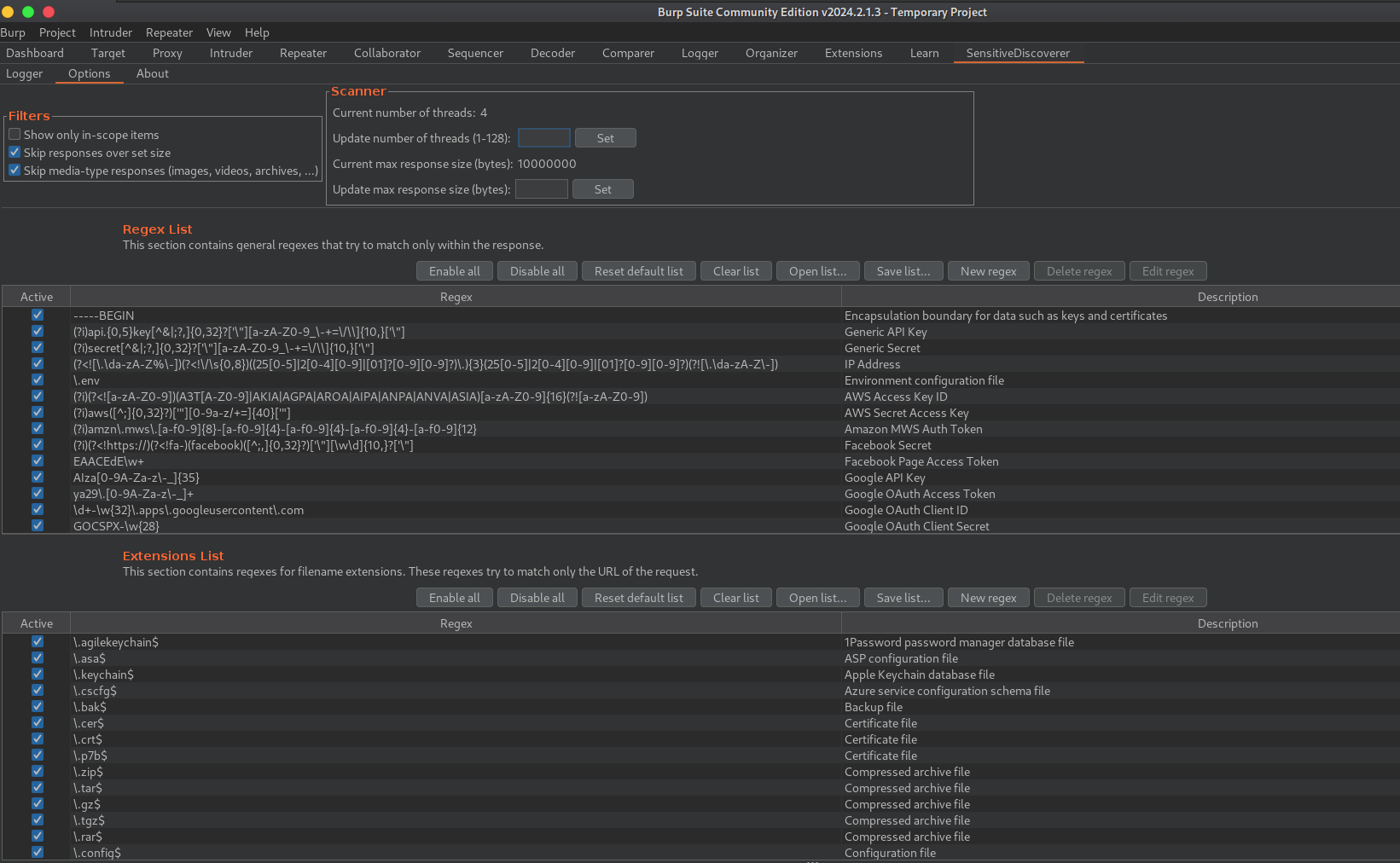
E extensão já vem com várias regex configuradas
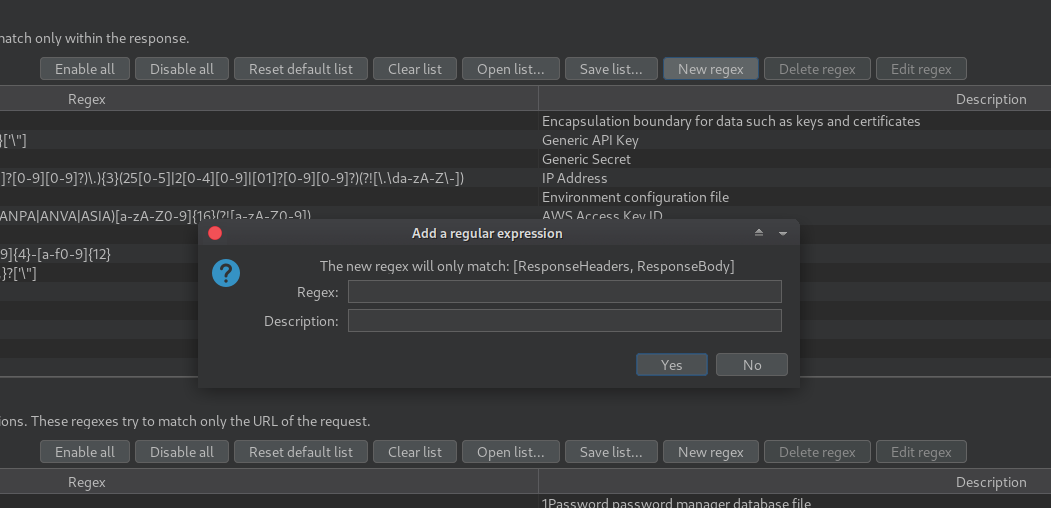
Você pode adicionar suas próprias expressões regulares clicando em New Regex
Nesse post tem uma regex que retorna bastante informações importantes e pode ser uma leitura interessante para estudo.
Sendo essa regex:
(?i)((access_key|access_token|admin_pass|admin_user|algolia_admin_key|algolia_api_key|alias_pass|alicloud_access_key|amazon_secret_access_key|amazonaws|ansible_vault_password|aos_key|api_key|api_key_secret|api_key_sid|api_secret|api.googlemaps AIza|apidocs|apikey|apiSecret|app_debug|app_id|app_key|app_log_level|app_secret|appkey|appkeysecret|application_key|appsecret|appspot|auth_token|authorizationToken|authsecret|aws_access|aws_access_key_id|aws_bucket|aws_key|aws_secret|aws_secret_key|aws_token|AWSSecretKey|b2_app_key|bashrc password|bintray_apikey|bintray_gpg_password|bintray_key|bintraykey|bluemix_api_key|bluemix_pass|browserstack_access_key|bucket_password|bucketeer_aws_access_key_id|bucketeer_aws_secret_access_key|built_branch_deploy_key|bx_password|cache_driver|cache_s3_secret_key|cattle_access_key|cattle_secret_key|certificate_password|ci_deploy_password|client_secret|client_zpk_secret_key|clojars_password|cloud_api_key|cloud_watch_aws_access_key|cloudant_password|cloudflare_api_key|cloudflare_auth_key|cloudinary_api_secret|cloudinary_name|codecov_token|config|conn.login|connectionstring|consumer_key|consumer_secret|credentials|cypress_record_key|database_password|database_schema_test|datadog_api_key|datadog_app_key|db_password|db_server|db_username|dbpasswd|dbpassword|dbuser|deploy_password|digitalocean_ssh_key_body|digitalocean_ssh_key_ids|docker_hub_password|docker_key|docker_pass|docker_passwd|docker_password|dockerhub_password|dockerhubpassword|dot-files|dotfiles|droplet_travis_password|dynamoaccesskeyid|dynamosecretaccesskey|elastica_host|elastica_port|elasticsearch_password|encryption_key|encryption_password|env.heroku_api_key|env.sonatype_password|eureka.awssecretkey)[a-z0-9_ .\-,]{0,25})(=|>|:=|\|\|:|<=|=>|:).{0,5}['\"]([0-9a-zA-Z\-_=]{8,64})['\"]|AIza[0-9A-Za-z\\-_]{35}Com o proxy ativado no Firefox, agora é a parte de verificar os links .js e procurar informações abrindo os links .JS
Nesse teste usarei o domínio tesla.com (disponível para bug hunting).
- Após abrir alguns links e esperar carregar (não esqueça de deixar a opção Intercet em On, como vimos anteriormente) já teremos as informações em HTTP History.
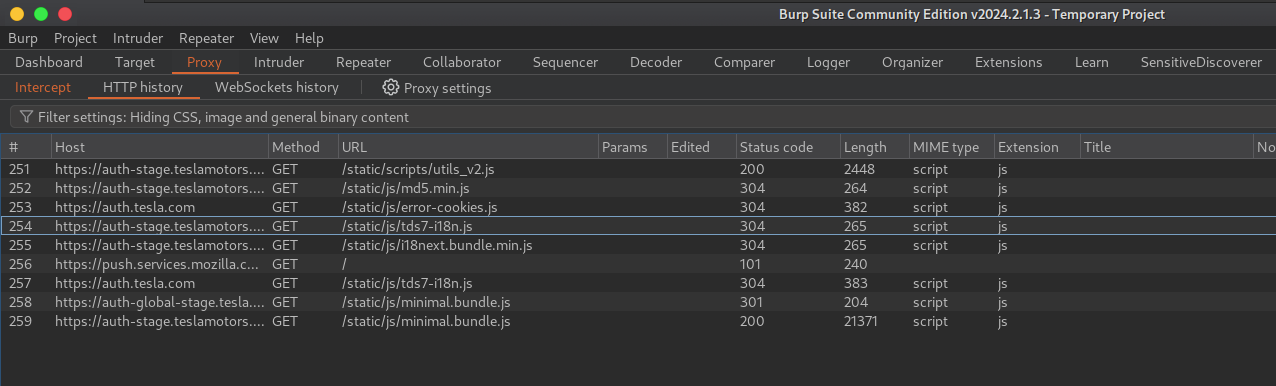
Verificando os dados com regex
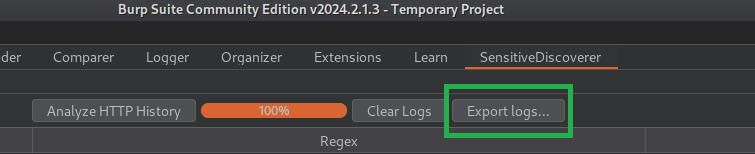
- Clique em “SesistiveDiscoverer”
- Clique em Analyze HTTP History

Você pode exportar os resultados clicando em “Export Logs”
Automatizando abertura dos links .js
Abrir um por um vários links é uma tarefa chata, dessa forma, você pode utilizar um script para abrir os links para você de forma a automatizar o processo.
import os
import webbrowser
import time
def list_files(directory):
# List all text files in the directory
files = []
for file in os.listdir(directory):
if file.endswith(".txt"):
files.append(file)
return sorted(files)
def open_links_from_file(file_path):
# Open each link from the file and add a delay
with open(file_path, 'r') as file:
links = file.readlines()
for link in links:
webbrowser.open(link.strip())
time.sleep(9) # Adding a 9-second delay
def main():
directory = "/path/to-jslinks/"
files = list_files(directory)
print("Select the text file with the links:")
for idx, file in enumerate(files, start=1):
print(f"{idx}. {file}")
choice = input("Enter the number corresponding to the desired file: ")
try:
choice = int(choice)
if 1 <= choice <= len(files):
file_name = files[choice - 1]
file_path = os.path.join(directory, file_name)
print(f"Opening links from the file {file_name} in Firefox...")
open_links_from_file(file_path)
else:
print("Invalid option.")
except ValueError:
print("Invalid option.")
if __name__ == "__main__":
main()Dessa forma a cada 9 segundos (ajuste da melhor maneira para seu ambiente) um link será aberto no Firefox.
Finalizando
Essa é a primeira parte, pretendo disponibilizar um modo de procurar informações utilizando um template do Nuclei e também um script em Python. Espero que seja informativo para seus estudos e que tenha ajudado em algo.